
Kontakt
Forschungsstelle Qumran-Digital
Akademie der Wissenschaften zu Göttingen
Friedländer Weg 11
D-37085 Göttingen
qumran[at]theologie.uni-
goettingen.de
![]()

Die Datenbank
Ein grundlegendes Arbeitsmittel des Projektes ist eine selbst entworfene Datenbank, in der alle Informationen gespeichert werden und die künftig im Open Access auch der Allgemeinheit zur Verfügung stehen wird. Die Datenbank enthält nicht nur den gesamten hebräischen und aramäischen Textbestand, für den das Wörterbuch geschrieben wird, sondern in ihr werden alle morphologischen und syntaktischen Bestimmungen zu den einzelnen Wörtern erfasst. Dabei ist es möglich, zu jedem Wort unterschiedliche Deutungen oder Vorschläge einzugeben. Eine Besonderheit ist auch die Eingabe von abweichenden Textlesungen, die in der Literatur zu finden sind, sowie die Verknüpfung der Texte mit Parallelstellen aus dem Textkorpus oder biblischen Texten.
 Auch die
XML-formatierten Wörterbuchartikel sind Bestandteil der Datenbank und
mit ihr direkt verlinkt. Auf diese Weise aktualisieren sich die
Textverweise und -zitate in den Artikeln von selbst. Zugleich ist damit
die Grundlage gegeben, das Wörterbuch mit seinen Verweisen
auf die Datenbank elektronisch über das Internet zugänglich zu machen.
Darüber hinaus kann auch eine Druckfassung automatisch ohne zusätzlichen Aufwand generiert werden.
Auch die
XML-formatierten Wörterbuchartikel sind Bestandteil der Datenbank und
mit ihr direkt verlinkt. Auf diese Weise aktualisieren sich die
Textverweise und -zitate in den Artikeln von selbst. Zugleich ist damit
die Grundlage gegeben, das Wörterbuch mit seinen Verweisen
auf die Datenbank elektronisch über das Internet zugänglich zu machen.
Darüber hinaus kann auch eine Druckfassung automatisch ohne zusätzlichen Aufwand generiert werden.
Die Bibliothek
Das Wörterbuch-Unternehmen verfügt über eine einzigartige Spezialbibliothek mit einer umfassenden Sammlung der Editionen der Handschriften vom Toten Meer einschließlich der Neu- und Teil-Editionen. Darüber hinaus enthält sie die einschlägigen Zeitschriften und Monographien. Für die Arbeit am Wörterbuch stellt sie schließlich neben den grundlegenden Grammatiken auch eine umfangreiche Sammlung wissenschaftlicher Wörterbücher zum Hebräischen, Aramäischen und den übrigen semitischen Sprachen bereit.
Vom Fragment zum Wörterbuchartikel
 Am Anfang der
Wörterbuch-Arbeit steht die Handschrift als solche. Häufig ist deren
Text in mehreren verschiedenen Editionen veröffentlicht. In den meisten
Fällen sind die Handschriften stark beschädigt, weshalb sie u.U. nur
schwer zu entziffern sind. Daher können Transkriptionen ein und
derselben Handschrift von Edition zu Edition voneinander abweichen.
Am Anfang der
Wörterbuch-Arbeit steht die Handschrift als solche. Häufig ist deren
Text in mehreren verschiedenen Editionen veröffentlicht. In den meisten
Fällen sind die Handschriften stark beschädigt, weshalb sie u.U. nur
schwer zu entziffern sind. Daher können Transkriptionen ein und
derselben Handschrift von Edition zu Edition voneinander abweichen.
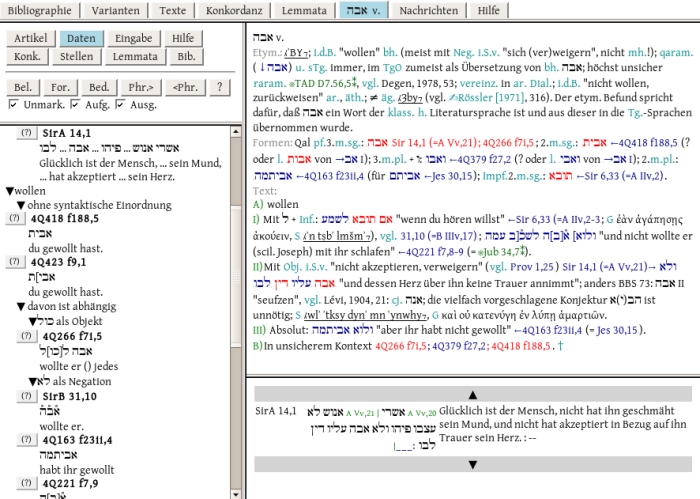 Um den tatsächlichen
Wortbestand der Qumrantexte zu erfassen, werden aus diesem Grund
zunächst die verschiedenen Editionen sorgfältig miteinander verglichen
und die dabei zu Tage tretenden Varianten in einer Datenbank
aufgenommen. In der Datenbank sind sämtliche Belege zu den einzelnen
Lemmata erfasst.
Um den tatsächlichen
Wortbestand der Qumrantexte zu erfassen, werden aus diesem Grund
zunächst die verschiedenen Editionen sorgfältig miteinander verglichen
und die dabei zu Tage tretenden Varianten in einer Datenbank
aufgenommen. In der Datenbank sind sämtliche Belege zu den einzelnen
Lemmata erfasst.
 Die einzelnen Artikel beruhen auf einer eigenen morphologischen und semantischen Analyse aller Belege des jeweiligen Lemmas.
Im Artikel werden nach einer etymologischen Einordnung des Lemmas in die hebräische bzw. aramäische Sprachgeschichte
sämtliche Formen eines Lemmas aufgeführt. Der sich anschließende semantische Teil dokumentiert die
unterschiedlichen Bedeutungen durch eine möglichst umfassende Auswahl an Belegen, die im Kontext zitiert
und übersetzt werden.
Die einzelnen Artikel beruhen auf einer eigenen morphologischen und semantischen Analyse aller Belege des jeweiligen Lemmas.
Im Artikel werden nach einer etymologischen Einordnung des Lemmas in die hebräische bzw. aramäische Sprachgeschichte
sämtliche Formen eines Lemmas aufgeführt. Der sich anschließende semantische Teil dokumentiert die
unterschiedlichen Bedeutungen durch eine möglichst umfassende Auswahl an Belegen, die im Kontext zitiert
und übersetzt werden.